データサイエンティストとしてよくDAG(Directed Acylic Graph、有向非巡回グラフ)という言葉を耳にしていますか?毎日耳にするでしょう。
DAGは、複数な非反復計算における一連の計算ステップとして定義されます。DAG’sはタスクであり、個別の量の作業を実行します。全体として、タスクはETLLジョブ、MLジョブ、CIジョブやデプロイメントジョブなどのより大きな作業を補います。
ツールが Argo 、Kuberflow と最も人気である Apache Airflowなど 多くあります。これらのツールは、ワークフロー全体として定義される個別のタスクでの使用法と表示作業の点で異なります。
最初は、チームとタスクがまだ小さい時、どれのツールでもいいでしょう。しかし、チームサイズが大きくなるにつれて、タスクとデータパイプラインの制限で崩壊とフラストレーションが増大してきます。MLツールを選択することが解決策ではなくなります。
- EC2インスタンスタイプの減少。
- 未知のソフトウェアで厄介さを増やします。
- カスタム回避策の増加に従うスケジューリングと再試行
- コミュニティに知られていない、または知識の欠如を知らないことを試みる。
通常、これらは、ツールを比較するために概念実証を行うことになるデータサイエンティストの一般的なシナリオです。
本稿で DS Solution は、4つの 機械学習プラットフォーム を比較していきます。
MLツールの選び方
実験的なトラッキングツールを検討する際には、以下6つのことを考えなければなりません。
- オープンソースソリューション:オープンソースまたは商用のソリューションを使用する必要がありますか?オープンソースと商用のソリューションの間に違いがあります。明らかな違いの一つは商用ソリューションに料金を払う必要がある一方、オープンソースは無料で使用することができます。また、オープンソースを利用するには、コミュニティからのサポートを受けることができ、ロックインを回避するためにカスタマイズが簡単に実行できます。それに対して、商用ソリューションは専門家からのサポートを受け、UI/UXと使いやすさに重点が置かれています。
- プラットフォームと言語サポート:多くの場合、データサイエンスはPythonや広く採用されている数フレームワークで行われます。実験的なトラッキングツールは、多くの場合簡略化されたトラッキングツールを提供しますが、あまり使用されていない言語やフレームワークを使うと、構造化されたヘルプドキュメントAPIの不足や一部の言語がサポートされないことが発生するおそれがあります。
- 実験データ保存:実験トラッキングツールはローカル、クラウドまたはハイブリッド(ローカルとクラウドを組み合わせて)で実験データを保存します。ローカルの場合、オンザフライで分析できるという利点がありますが、クラウドは知識の保存と共有が特徴です。最良のソリューションは両方を利用するのですが、すべてのツールがそれをサポートするわけではありません。
- カスタム可視化:様々なトラッキングツールの重要な要素はさまざまな実験を視覚的に表示する機能です。それにより、結果をより迅速で分析し、中断することができます。正しいグラフは他の人に結果を伝えることに役立ちます。可視化は複雑なデータを簡潔かつ明確に表示する最もいい方法です。
- ステップと使用の単純さ:利便性は重要な要素です。一部のツールは協力で各データをトラックすることができますが、データサイエンスワークフローで使用することが難しいです。不快なプレミアムUI/UXを備えているツールもあります。その一方、クリーンでエレガントなインターフェスを備えているツールもあります。
- スケーラビリティ:実験トラッキングはチームと実験のボリュームに基づく必要があります。100回の実験をサポートするツールは、10万回の実験をサポートしません。大規模な実験を計画する場合、選択したツールが実験をどのようにサポートするか確認する必要があります。
データサイエンスMLコードは小さなコードのセットであるため、その周りには、インフラストラクチャ要件、スケーリング、データ抽出、タグ付け、分類など差別化されていない重労働があり、その回避策の実行には多くの時間が費やされています。
なぜ機械学習ならKubernetesを選ぶのか?
It’s a great platform, there are 3 requirements for ML,
MLは優れたプラットフォームです。ML Platformには 以下3つの要件があります。
- 組み合わせ可能性:データのタッグ付け、データの分類、データの取り込み、トレーニング、推論は様々なマイクロサービスである可能性があります。Kubernetesはマイクロサービスを調整し、機械学習プラットフォーム全体をビルドする役割があります。
- 移植性:これらのインフラストラクチャを実行していますか。それで、これらのインフラストラクチャが移植可能であるかどうか確認する必要があります。モバイル、デスクトップ、またはタブで作業している場合は、これらの様々なコンピューティング環境、様々なクラウドで機能する環境が必要でしょう。Kubernetesは、様々なコンピューティング環境で機能する基本的なコンピューティングレイアウトを提供します。
- スケーラビリティ:GPU、推論、インフラストラクチャとスケーリングを追加しようとする場合、Kubernetesはくたすたーをスケーリングし、容量とワークロードを追加します。
そのため、大きなクラスターとマシン実行コードをトップで実行する場合、Kubernetes は機械学習に適しています。
データサイエンティストとしては、モデル、モデルストレージの場所、UI、使用するツールとフレームワーク、使用するアプリがコンピューティング環境に適したバージョンであることを理解するでしょう。
それに、データサイエンティストとしては、パソコン、トレーニングリグ、およぼクラウドでの本番環境で作業する時に、独自の組み合わせをイメージするでしょう。そこで、KubeFlowが役に立ちます。
KubeFlow
KubeFlowはKubernetesで構築され、抽象化、開発、デプロイとマップの簡単な方法を提供します。それにより、Kubernetesプラットフォームの管理に役立ちます。
Kubeflowはk8sでの移植可能で、スケーラブルなエンドツーエンドのワークフローを開発、デプロイ、それに管理を簡単いできるように機能する、コンテナ化された機械学習プラットフォームです。
KubeflowはML用の「ツールキット」であり、緩く結合されたツールとブループリントです。
データサイエンティストは、PyTorch、TensorFlowやCRDなどのフレームワークをトレーニングに利用しましたが複数のノードに分散するモデルを探しています。モデルトレーニングはKubeflowインストールの一部であるCRDです。
モデルの提供:フェアリングPython SDK、トレーニングコード、Dockerイメージへの変換、デプロイ。これにより、データサイエンティストは、本番環境にインストールすることができます。
ハイパーパラメータの調整、学習率、CNNネットワークの層数は、モデルがどれだけ効率的に実行されるかを識別します。これらのツールセットはすべてKubeflowの一部として提供され、KubernetesでのMLエクスペリエンスを簡素化します。

Airflow
Aiflowの運用チーム向けのPythonベースオーケストレーションプラットフォームはワークフローを表示する最もいいUIがあります。処理に最適で、人気であるのはワークフローを1万スケーリングに拡大することです。
AirflowはAirbnbにより開始されました。Airflowのサポートコミュニティは500名のアクティブメンバもいます。
- DAG’s:DAGは簡単に作成できます。Airflow 2.0ではPythonOperatorsを使用しています。DAG’sはXComと依存関係に特別な注意を駆らっています。
- RestAPI:RestAPIはAirflowのハイライトです。AIP-32はOpenAPI仕様を使用した完全なREST APIをサポートしています。
- Scheduler:Airflowは水平方向のスケーラビリティが所有するため、そのSchedularは非常に速いです。Airflowは高可用、スケーラビリティ、パフォーマンスを実現し、同時に複数のSchedularを実行することができます。
- パッケージのインストール:Airflowには60以上のパッケージが所属しているため、既存のパッケージと必要なパッケージでAirflowはよりカスタムしやすくなります。
広く使用されること、完全にカスタマイズされた一貫性のあるランタイムはAirflowの主なメリットです。
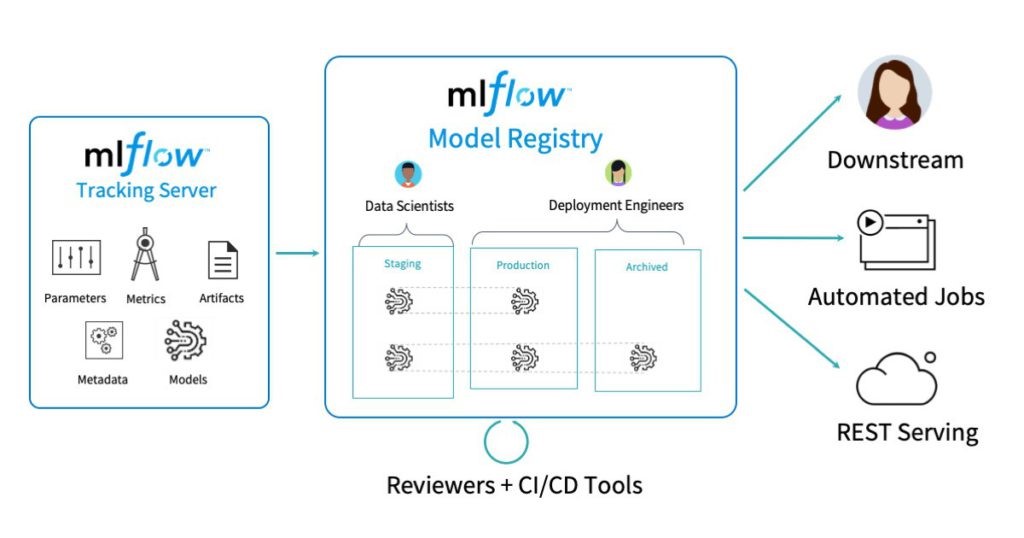
MLFLow
標準化された機械学習プラットフォームをみつけることは難しい作業です。Facebook FBlearner、Uber Michelangelo、Google TFXなどのカスタムMLプラットフォームは標準化されたMLプラットフォームがいくつありますがアルゴリズムが少ないです。それらは企業向けのインフラストラクチャであるため、シングルデータサイエンティストは利用できません。
MLFlowは、オープンフレームでビルドされたMlライフサイクルのオープンソースプラットフォームです。MLの既存アルゴリズムとインフラストラクチャを簡単に統合
オープンな統合プラットフォームは、既存のフレームワークとアルゴリズムを利用して、MLプラットフォームに統合する方法を提供します。
- MLflowは機械学習のすべてのライブラリで動作します。
- 簡単に再現できます。同様のMLコードはクラウド、ローカルマシンやノートブックなど様々な環境で実行できるように設計されます。
- 読みやすい、MLflowは小規模なチームだけでなく大規模な組織にも適しています。MLflowは数千人の実践者がいます。
- トラッキング、プロジェクト、モデルに焦点を当てます。MLFlowはメタデータを保存するための中央データベースをトラックします。MLFlowを利用したプロジェクトは、実行環境を問わず同じように実行される、再現可能な自己完結型のパッケージ形式モデルです。様々な展開ツールをサポートするモデル形式を提供します。
MLFlowはパラメーター、メトリック、ソース、バージョン、アーティスト、タグとメモなどの主要な概念に中心しています。MLFlowでは、データが任意の場所に保存されます。また、MLFlowはREST、Python、JAVA、またはR.を利用したトラッキングAPIで構成されています。この情報は集中トラッキングサーバーによって集約されます。そのサーバーは、多くの人気のあっるインフラストラクチャで実行するように設計されたプラガブルがあります。
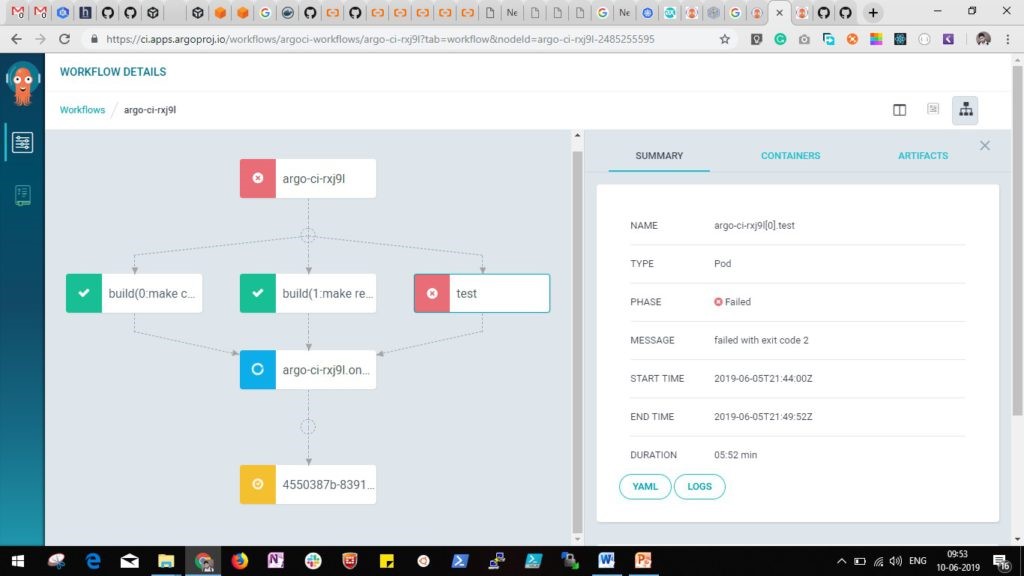
Argo:
インフラストラクチャとサービスによる継続的な開発とスケーリングはどのR&Dチームにとっても困難です。これは、クラウドのサポートとコンテナーで自動化や視覚化による実行できます。スケーラブルなフーパーは、CI/CD、テスト、実験とデプロイメントなどのソフトウェア開発ライフサイクルとワークフローを管理します。
コンテナネイティブのワークフローエンジンは、Kubernetesワークフローをフィードし、管理します。それに、ワークフローの実行をスケーリング及び調整します。
Argoはワークフローエンジン、ネイティブアーティファクト管理、アドミッションコントロール、組み込みのDocker-in-dockerポリシーなどで組み合わせられます。Argoは主として以下の場合で利用されます。
- 伝統的なCI/CDパイプライン
- シーケンス及び並列ステップの依存関係を持つジョブ
- .複雑な分散アプリケーションのデプロイメントを調整します。
- ワークフローの時間/イベントベースの実行を可能にするポリシー
各ステップはコンテナーを利用し、実行されます。Argoは、ワークフローの各ステップ間の制約を指定するための簡単かつ柔軟なメカニズムと、ステップのアウトプットを後続のステップへのインプットとしてリンクするためのアーティファクト管理を提供します。アーティファクト管理とワークフローを統合することは、移植性の実現、それに効率向上と単純化にも重要です。ワークフローステップをコンテナーから全体的に構築することにより、すべてのステップ実行とステップ間の相互作用を含むワークフロー自体は、ソースコードのように指定および管理されます。
統合されたこんたなーネイティブワークフロー管理システムはもう一つのメリットがあります。それは、ワークフローをコードのように指定及び管理すること(YAML)ができます。Argoでは、ワークフローは移植可能だけではなくバージョン管理も可能です。あるArgoシステムで実行されるワークフローは、別のArgoシステムでも同様実行されます。新しいArgoシステムを、以前のシステムで使用されていたものと同じソースレポジトリとコンテナレポジトリにポイントするでけで、それができます。
まとめ:
最適のML Platformを選ぶには、迷いやすいでしょう。本投稿では、MLプラットフォームを選択するための基準および、業界で広く使用されている上位のMLフレームワークについて説明しました。